Las transacciones son operaciones atómicas (aquellas que se ejecutan asegurando ACID) que se realizan en las BBDD.
- Atomicity: implica que se ejecuta todo o nada (todos los pasos de una transacción o ninguno), requiere de protocolos de recuperación.
- Consistency: está relacionado con mantener los datos coherentes siguiendo unas reglas relacionales de la BDD.
- Durable: tras la ejecución de la operación atómica, se asegura de que se ha registrado el cambio de forma permanente. Requiere de protocolos de recuperación también.
- Isolation: implica seriabilicidad, esto es, que las operaciones atómicas se ejecutan, conceptualmente, de forma serial (una tras otra, sin solapamientos); aunque en la realidad eso no es del todo cierto pero el efecto final es el mismo. Requiere de protocolos de control de concurrencia.
La motivación de uso de operaciones atómicas es la resolución del problema de una transacción bancaria, en la cual la operación ha podido haberse quedado a medias tras la resta de dinero de la cuenta A debido a algún fallo y no llegar a sumarse en la cuenta B. Sin mecanismos para asegurar ACID, tendríamos transacciones bancarias que se han quedado a medias y, por ende, clientes que han perdido su dinero en un limbo de ceros y unos.
Transacciones centralizadas
Los datos tienen operaciones de lectura y escritura.
Las BBDD centralizadas tienen los datos en un solo nodo y puede haber acceso concurrente a los datos.
Una transacción se ha completado correctamente si anota un «COMMIT», o incorrectamente si ha declarado un «ABORT» explícitamente o bien implícitamente si el sistema ha crasheado de algún modo y no se ha apuntado ni COMMIT ni ABORT.
Protocolos de control de concurrencia
En las transacciones de las BBDD, protocolo de concurrencia más común es el «Two Phase Locking» (bloqueo en dos fases).
Two Phase Locking (2PL)
Cada ítem de la base de datos que pueda leerse/escribirse (una fila, una tabla entera, etc) tendrá asociado una posible operación de lock (acquirement ó bloqueo) para asegurarse de que sólo esa transacción va a usar el ítem; y una operación de unlock (release ó liberar) para liberar los ítems bloqueados y que otras transacciones puedan usarlos.
Normalmente, estos ítems que pueden ser bloqueados o adquiridos serán filas/tuplas de una tabla o directamente una tabla entera de la BD.
Hay dos tipos de locks:
- de lectura (permiten otras lecturas concurrentes pero ninguna escritura)
- de escritura (que no permite ningún tipo de concurrencia).
El protocolo se compone de dos fases: growing phase (o fase de crecimiento) y la shrinking phase (o fase de decrecimiento):
- Growing phase: la transacción primero adquiere todos los ítems que necesita para proceder a realizar una operativa.
- Shrinking phase: la transacción va liberando los ítems uno a uno tras realizar las operaciones deseadas. Cuando se comienza esta fase ya no se puede volver a bloquear ningún ítem hasta que la transacción haya finalizado (para asegurar la serialización de la concurrencia).
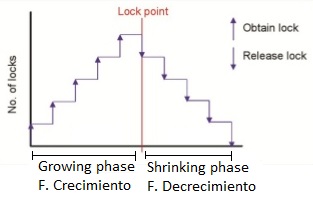
NOTA: Es posible que durante la fase de decrecimiento, los locks liberados vayan siendo adquiridos por otros procesos. Esto no es problema ya que se quedarán bloqueados hasta poder obtener todos los que necesiten para continuar con la operativa.
Deadlocks
Existe la posibilidad de que se produzca un deadlock, esto es, un interbloqueo en el que dos transacciones se bloquean la una a la otra en la espera indefinida de la liberación de un recurso; por ejemplo:
Una transacción T1 bloquea un ítem X mientras que la transacción T2 bloquea otro ítem Y, luego la transacción T1 pide el ítem X y se queda bloqueada a que T2 la libere, de la misma forma T2 pide el ítem Y y se queda bloqueado de forma infinita hasta que T1 libere a Y.
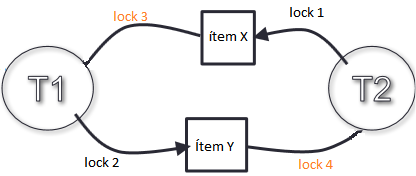
Esto se puede solucionar fácilmente con:
- Timeouts: abortar una transacción si queda bloqueada por más de X tiempo.
- Transacciones con timestamps: una transacción sólo esperará ante el lock de una transacción más antigua que ella (las transacciones más antiguas tienen mayor prioridad en el lock).
- Wait for grafs: detectar ciclos y abortar transacciones.
Protocolos de recuperación
Existen tres tipos de fallos en los sistemas transaccionales:
- Transaccional: un fallo generado en la misma transacción (un error en tiempo de ejecución que no tira el sistema abajo, son aborts explícitos de las transacciones). Mantiene la memoria volátil.
- De sistema: detenimiento del procesador, eliminación de la memoria volátil.
- De disco: almacenamiento corrupto de los datos.
Para los fallos transaccionales y de sistema se usa el mismo método (ya que si arregla el fallo del sistema también debería arreglarse el transaccional); que en nuestro caso será el método «Undo/Redo«.
Para fallos de disco se hace mirroring de almacenamiento (replicación de datos).
Método Undo/Redo
Las escrituras a los Logs se hace en un almacenamiento estable y directo (sin caché).
Se van haciendo checkpoints en los logs cuando la caché ha sido volcada correctamente a la BD (para evitar tener que recorrer todo el log).
Este método hace uso de esta arquitectura. Cuando hay un fallo de sistema o de transacción, se parte de un backup de la BD (o un checkpoint) y se lee el log correspondiente a los datos que aún no hayan sido «estabilizados».
En el log tendremos inicios de transacciones, valores antiguos (antes de escribir valores nuevos en la BD, los llamados «valores de undo»), valores nuevos (también llamados «valores de redo», justo antes de hacer el commit) y las anotaciones de COMMITs o ABORTs de las transacciones.
Cuando hay un fallo la recuperación se hace:
- Primero el undo de las transacciones no completadas o abortadas desde el final del log al principio de este; esto es, mira los valores antiguos y los vuelve a escribir en la BD para dejarla como estaba (undo).
- Luego el redo de las transacciones completadas (con COMMIT) desde el inicio del log hasta el final; esto es, mira su valor nuevo y lo escribe de nuevo en la BD (redo).
Replicación de datos: Transacciones distribuidas
Para tener escalabilidad horizontal, alta disponibilidad y tolerancia a fallos, los datos se distribuyen en diferentes nodos (conformando así un sistema distribuido), por tanto, requiere múltiples SGBDs y protocolos de control de concurrencia global (Strict 2PL), protocolos de atomic commitment (2PC) y algún modelo para conseguir coherencia serializable (ROWAA o Quorums).
Protocolos de concurrencia global
Strict 2 Phases Locking (Strict 2PL)
Cada SGBD tiene su propio sistema de recuperación de datos y de control de concurrencia (bloqueará sus datos locales, pero la liberación se hace sólo después de que termine la transacción, esto es, después del COMMIT o del ABORT para así facilitar el algoritmo de Two Phases Locking de forma distribuida – llamado «Strict 2 Phases Locking Protocol»- el cual sigue teniendo los mismos problemas de deadlock, sólo soluciona el problema del algoritmo distribuido).
Protocolos de atomic commitment
Two Phase Commit (2PC)
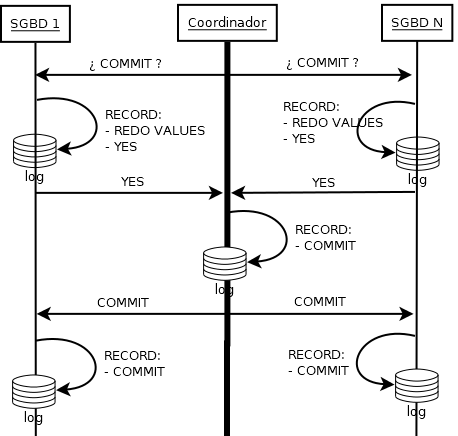
Para conseguir realizar una transacción distribuida, se usa este algoritmo de Atomic Commitment en dos fases.
El nodo que inicia la transacción es el nodo coordinador, los demás se les llama SGBD a secas o «data managers».
En la primera fase el coordinador, cuando quiere hacer un COMMIT, le pide a todos los SGBD el voto de COMMIT (YES/NO).
En la segunda fase el coordinador apunta COMMIT en su log y manda la confirmación de COMMIT a todos los SGBD si todos votaron YES, en otro caso se apunta y manda un ABORT.
Tolerancia a fallos del algoritmo:
Premisas
- Todos los SGBD apuntan en su log los valores de redo y el voto YES cuando van a contestar YES a la votación.
- Todos los SGBD apuntan en su log el estado ABORT de la transacción cuando va a contestar NO a la votación.
- Todos los SGBD apuntan en su log el estado COMMIT o ABORT cuando llega la confirmación/orden final del coordinador.
- El coordinador apunta al iniciar la transacción los IDs de los SGBD implicados.
Situaciones
All Yes
Some No
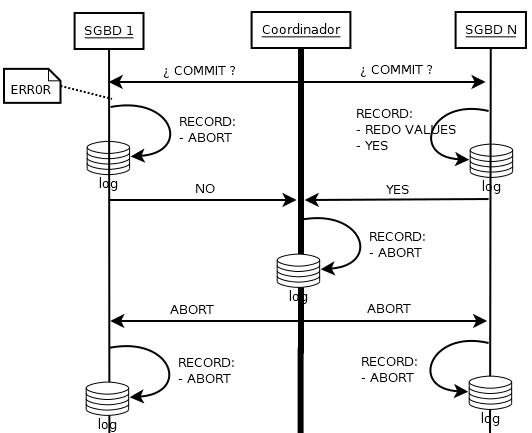
Timeout failures
- Si algún SGBD no vota (timeout), el coordinador manda y apunta un ABORT
- Si algún SGBD no recibe el COMMIT del coordinador (timeout), interpreta ABORT. Posteriormente el coordinador manda un ABORT a los demás SGBD.
Voting Timeout
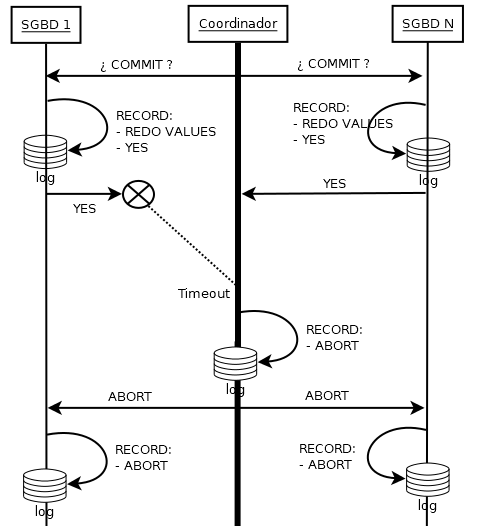
Coordinator Command Timeout
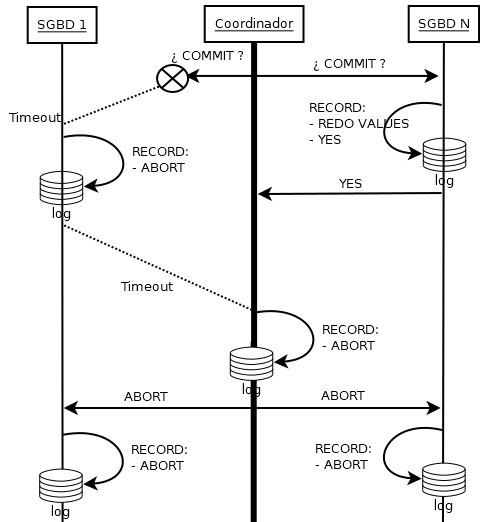
UNDO/REDO en 2PC
Se sigue el mismo procedimiento del undo/redo en sistemas centralizados, pero añadiendo que si un SGBD encuentra apuntado un voto YES sin COMMIT, debe preguntarle al coordinador qué debe hacer (es decir, qué ocurrió en esa transacción, COMMIT o ABORT).
Coherencia serializable
Para conseguir que todas las réplicas de la BDD mantengan la misma información para todos los clientes, se debe usar algún modelo que consiga implementar coherencia serializable, por ejemplo:
- Algoritmos ROWAA (Read-one-write-all-approach)
- Uso de Quorums
ROWAA (Read-one-write-all-approach)
ROWAA funciona si el protocolo de multicasting usado en el SD es FIFO.
Este modelo tiene en cuenta dos factores a la hora de conseguir la coherencia:
- Localización de la transacción (Dónde):
- Primary-secondary: si hay una réplica líder (primary) que atiende las transacciones DE ESCRITURA (el resto de réplicas pueden atender transacciones de lectura como norma general) y propaga los cambios a las demás (secondaries).
- Anywhere: si todas las réplicas pueden ejecutar transacciones.
- Estrategia de sincronización (Cuándo):
- Eager (ansioso): Las actualizaciones se mandan ANTES del commit (mayor consistencia pero mayor latencia).
- Lazy (perezoso): Las actualizaciones se mandan DESPUÉS del commit.
Eager Primary
Desventaja: mayor latencia al tener que esperar la respuesta de las demás réplicas.
- Las lecturas se realizan en cualquier nodo sin necesidad de adquirir locks (pero debe respetar los locks de escritura).
- Las escrituras se realizan en el nodo primario y adquiere el lock de escritura (con Strict 2PL) avisando a las demás réplicas (no espera ACKs).
- Los ABORTS de escritura se difunden (los de lectura no).
- Los COMMITS de escritura se difunden mediante 2PC (los de lectura no).
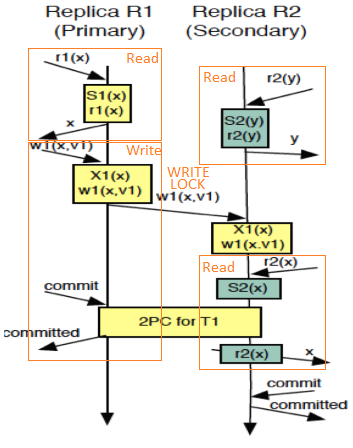
Eager Anywhere
Desventaja: propenso a deadlocks y a transacciones abortadas innecesariamente.
- Todos los nodos pueden leer y escribir.
- Escribir = Adquirir lock GLOBAL, para lo cual avisa a los demás nodos (Petición para realizar acquire del lock de escritura) y espera ACKs.
- Los deadlocks distribuidos (debidos al delay en la transmisión de la petición del lock) se arreglan al recibir una PETICIÓN de acquire de otra transacción antes de que esa otra transacción haya respondido a nuestra petición de adquisición del lock. Nuestra transacción realiza ABORT y le devuelve el ACK a la otra transacción.

Acrónimos
ACID: Atomicity, Consistency, Isolation & Durable.
BBDD: Bases de Datos.
BD/BDD: Base de Datos.
SGBD: Sistema Gestor de Base de Datos.
Deja una respuesta
Lo siento, debes estar conectado para publicar un comentario.