Introducción
Un Sistema Distribuido es un conjunto de computadoras (nodos) separadas físicamente y conectadas entre sí por una red de comunicaciones que cooperan, de alguna forma, para conseguir un objetivo común, normalmente relacionado con conseguir alta disponibilidad de servicios (high availability) o con el alto rendimiento computacional (high performance).
- La alta disponibilidad se basa en la replicación de procesos o datos para que, si se cae un nodo, los demás puedan continuar ofreciendo el servicio.
- El alto rendimiento se basa en la distribución de trabajo y balanceo de carga computacional soportable por cada nodo para resolver un problema en conjunto.
Debido a la no-fiabilidad de los enlaces de comunicación, el sistema puede sufrir fallos (ya que normalmente se usan comunicaciones a través de Internet) y a eventuales caídas de los nodos. Los SSDD deben ser conscientes de estos fallos y aplicar algún nivel de tolerancia a fallos según las necesidades del SD a implementar (o incluso ignorarlo si el SD es capaz de continuar sin tener que sustituir los nodos caídos).
Problemas en la cooperación global de los procesos en un SD
- La comunicación puede ser asíncrona (delay indeterminado en la comunicación).
- Existe la posibilidad de que haya fallos en los enlaces de comunicación.
- Los procesos no tienen por qué compartir el mismo reloj (problemas de timing, problemas de orden temporal entre eventos, problema de lectura de datos diferentes, etc).
- Los procesos no tienen por qué compartir la misma memoria (problemas para obtener el estado actual de la memoria global del programa, ya que no se puede obtener el estado de forma instantánea, habrá delay entre los nodos cuando se solicite el estado actual de la memoria de cada uno de ellos, resultando en una «fotografía» con trozos de información diferentes en el tiempo).
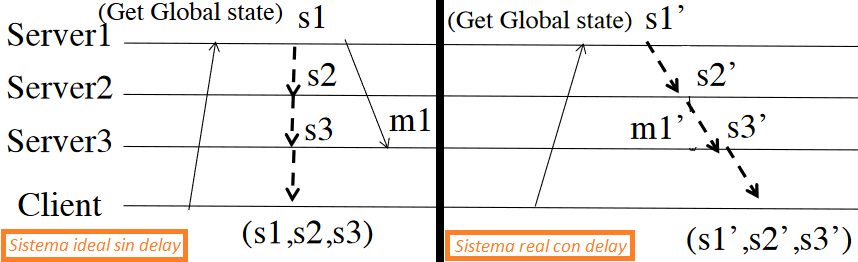
s1, s2 y s3 son los estados de cada nodo
Abstracciones de los SSDD
Para poder entender los SSDD, se separan los niveles de abstracción en dos:
- Nivel básico: relativo a la capa física del sistema, esto es, los procesos (entidades básicas de computación en un SD, los cuales pueden ser ordenadores enteros, un procesador, un thread…) y los enlaces de comunicación (la red de comunicación).
- Nivel de aplicación: patrones utilizados en los SSDD para poder conseguir la cooperación inter-proceso tolerante a fallos (y que solucione todos los problemas que se han enumerado antes: timing, memoria distribuida, etc).
Abstracciones de nivel de aplicación
Algoritmos y abstracciones que ayudan a solventar problemas comunes en los SSDD:
| ABSTRACCIÓN | SOLUCIÓN AL PROBLEMA DE… |
|---|---|
| Relojes lógicos | El orden temporal al no tener un reloj global. Se basan en el orden de eventos/procesos global. |
| Estados globales distribuidos | Una memoria distribuida a lo largo de una red y por ende no poder obtener el estado global de forma instantáneamente. |
| Comunicaciones fiables | Fallos y asincronía (delay indefinido) en la comunicación. Ej: TCP. |
| Multicasting primitivo | La no existencia de hardware síncrono y fiable para el envío de datos a un grupo específico de procesos. Estos algoritmos implementan diferentes niveles de QoS. Ej: MQTT, Publisher-subscriber. |
| Memoria compartida | La compartición de memoria entre procesos. |
| Consenso | Decisión de un valor global igual a todos los procesos para que todos usen los mismos valores. Ej: Paxos. |
| Detectores de fallos | El desconocimiento de si un proceso ha fallado (debido a la asincronía). Ej: HearBeats. |
| Atomic Commitment | Decisión en la ejecución de un paso sólo cuando TODOS los procesos están de acuerdo en ello, en otro caso no se da ese paso. Ej: 2 Phase Commitment. |
| Elección de líder | Elección (entre todos los nodos del sistema) de un líder (un nodo maestro que dirige al resto de procesos). |
Modelo de un SD
Un SD está definido por 5 componentes:
- Computación: Cómo se realiza la computación en el SD.
- Procesos: Tipos de procesos.
- Links (enlaces): Propiedades que deben cumplir los enlaces.
- Timing: Tipos de delay en la red (links).
- Paradigma de comunicación: Cómo se comunican los procesos entre sí.
Computación
Los procesos son la unidad de computación.
El sistema puede estar compuesto por un número fijo de procesos (sistema estático) o por un número variable (sistema dinámico).
Los procesos pueden conocerse entre sí (membresía conocida ) o no (membresía desconocida).
Los procesos se comunican intercambiando mensajes identificados de forma unívoca con el par:
[ id_proceso + numero_sección ]
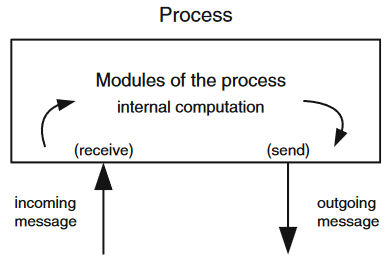
Cada proceso es considerado un autómata o máquina de estados, es decir, un conjunto de pasos determinista; cada paso consiste en recibir un mensaje, ejecutar un proceso en el nodo local (que puede ser nulo, o sea, no hacer nada) y devolver un mensaje.
Procesos
Los procesos de un sistema distribuido se clasifican según la naturaleza del fallo que pueden sufrir (es decir, el tipo de fallo que se puede esperar que ocurra en los procesos del sistema).
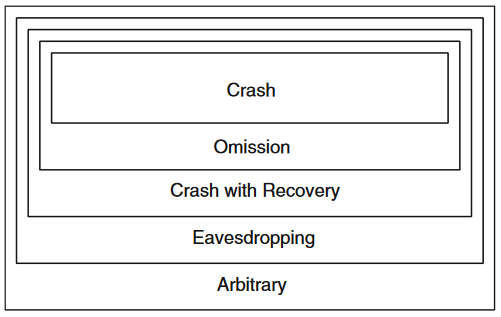
Tipos de procesos de más sencillo a más complejo (de arriba a abajo). La capacidad de solventar los fallos más complejos implica solventar los más sencillos.
- Crash: si existe la posibilidad de que el proceso falle después de un tiempo «T» y por ende que los algoritmos pueden llegar a tener, como máximo, un número «F» de fallos.
- Omisión: si existe la posibilidad de que el proceso no envie o reciba un mensaje en algún momento dado, provocando una desviación del algoritmo (normalmente se relaciona con buffer overflow o congestión de la red).
- Crash-recovery: si existe la posibilidad de que el proceso, tras un fallo de tipo «Crash», pueda recuperarse, estando un tiempo inoperativo desde que se cayó hasta que se recuperó. Normalmente se usa almacenamiento no-volátil para la recuperación.
- Arbitrario/Byzantine: si existe la posibilidad de que el proceso se desvíe de la ejecución de forma arbitraria (normalmente debido a fallos maliciosos). Son los más complejos/costosos de tolerar (de crear mecanismos que sean tolerantes a este tipo de fallos).
Enlaces de comunicación (link)
Los enlaces (links) representan los componentes de la red de comunicaciones del sistema distribuido.
En general se considera que cada par de procesos está conectado por un enlace bi-direccional
Aunque en la práctica se pueden usar otras topologías de conexión (fully connected mesh, ethernet, ring, internet…) las cuales utilizan algoritmos de enrutamiento cuando el sistema no esté totalmente conectado entre sí.
Los enlaces pueden provocar pérdidas de mensajes (omisión) o retraso excesivo de entrega del mensaje (timing); para solucionarlo los mensajes se retransmiten mediante el uso de enlaces «Fair-loss«.
Enlaces Fair-loss (propiedades):
- Fair-loss: si un proceso A manda un número infinito de mensajes a un proceso B entonces B recibirá un número infinito de mensajes siempre y cuando A no caiga.
- Duplicación finita: Si A manda un mensaje un número finito de veces, a B no le pueden llegar infinitas veces dicho mensaje.
- No-creación: Los mensajes no pueden haberse creado de la nada (si un mensaje llega a algún proceso B es porque algún proceso A lo ha creado previamente).
Timing
Debido a la falta del reloj global y a las incertidumbres de delay de los mensajes a través de los enlaces (timing) , se clasifican 3 tipos de sistemas distribuidos en este aspecto: síncronos, asíncronos y parcialmente síncronos.
- Sistemas asíncronos: el tiempo de procesamiento de cada proceso y el delay en la transmisión de mensajes es indefinido (situación realista, tipo internet). En el momento en el que usan técnicas tipo «timeout» para establecer límites de tiempo, el sistema deja de ser asíncrono. Estos sistemas hacen imposible la aplicación de las abstracciones de: consenso, atomic broadcast y membership service.
- Sistemas síncronos: se conoce el tiempo máximo de procesamento y de transmisión de mensajes (situación menos realista, sistemas de tiempo real). Es más fácil detectar los procesos caídos.
- Sistemas parcialmente síncronos: son sistemas asíncronos en los cuales los tiempos máximos de procesamiento y transmisión son adaptativos: se comienza con un timeout aleatorio y se determina cuál va a ser el tiempo real de espera (upper bound) usando alguna técnica, ya sea usando el último pico máximo de timeout como el timeout para los procesos/enlaces, usando una media aritmétcia de picos, etc. Es una situación más realista que los dos tipos de sistemas anteriores.
En el mundo real, normalmente se tienen Sistemas Distribuidos asíncronos o parcialmente síncronos, es por ello que este será el ámbito de estudio de los SSDD; de hecho, cuando hablamos de un SD, suponemos que son de este tipo ya que los SSDD síncronos se les suele llamar sistemas de tiempo real.
Asincronía, Coherencia y Particiones de red
Cuando nos enfrentamos a sistemas distribuidos asíncronos o parcialmente síncronos, hay subyacentes tres problemas principales que hay que solventar:
1.- Particiones de red: Parte del sistema puede quedar aislado de la mayoría de nodos (debido a un corte en las comunicaciones entre ambos grupos de nodos). Un grupo acabará teniendo unos datos/estados diferentes al otro, es lo que se conoce como incoherencia.
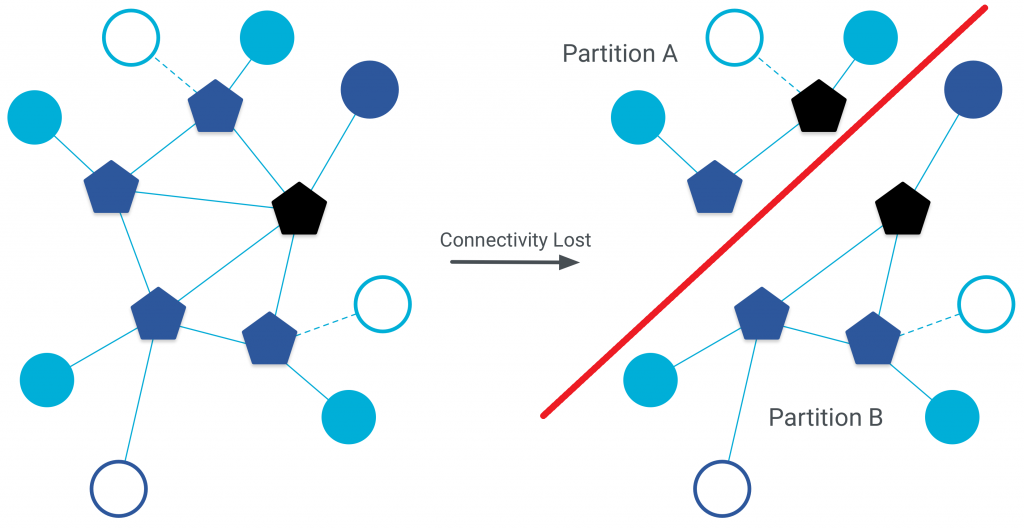
2.- Asincronía: Al existir un delay no-uniforme en las comunicaciones, habrá información desfasada en cada nodo (incoherencia).
3.- Fallos en procesos y enlaces: independientemente del tipo de error que soporte el proceso, el tiempo entre el fallo y la recuperación del proceso también provocará un desfase entre la información del sistema y la del nodo recuperado (incoherencia).
Por tanto, en los SSDD tenemos problemas de disponibilidad (availability), particiones de red y de coherencia/consistencia de datos y estados. Como se mencionó en la introducción, estos problemas pueden ser asumibles e ignorados en algunos SSDD, pero, en general, todos deben ser conscientes de todos o algunos de ellos.
Paradigmas de comunicación
Existen dos tipos de paradigmas de comunicación entre entidades: directa e indirecta.
Paradigma de comunicación directa: Es comunicación uno-a-uno, los emisores y receptores se conocen entre sí (membresía conocida), los mensajes tienen ID del emisor y del receptor y deben estar «online» a la vez.
Ejemplos: Paso de mensajes (con sockets), protocolos de request-reply (ej: cliente-servidor), RPC (Remote Procedure Call), RMI (Remote Method Invocation).
Paradigma de comunicación indirecta: Normalmente es comunicación uno-a-muchos. Los emisores y receptores no se conocen (desacoplamiento espacial), por tanto se requiere de una entidad intermediaria (habitualmente llamada «broker»); los nodos tampoco tienen que estar corriendo a la vez para que llegen los mensajes a los destinatarios (desacoplamiento temporal).
Ejemplos: Sistemas Publish-subscribe (MQTT), Memoria compartida distribuida.
¿Desea saber más?
Aplicaciones de los SSDD
Diseminación de información (pub/sub)
Este tipo de SD tiene procesos que producen información (publishers) y procesos que consumen información (subscribers), lo que se conoce como «modelo pulish-subscribe».
Se usa la abstracción de «multicasting primitivo» para conseguir que sólo un cierto grupo de consumidores (procesos) reciban un tipo de dato en concreto de los productores.
Aplicaciones de control
Sistemas que controlan la ejecución de una actividad física.
Suelen usar sensores para obtener datos del entorno físico y actuadores para provocar algún cambio en dicho entorno.
Para conseguir tolerancia a fallos y que la actividad física se lleve a cabo correctamente (a través del actuador), se tienen réplicas de los procesos en diferentes nodos, que funcionan a la vez y en paralelo para que, en caso de que falle uno, los otros sigan funcionando.
Como existe el problema de que hay diferentes relojes en cada nodo, y por ende puedan están desincronizados (desfasados, consumen diferentes datos/estados del sensor) y tener diferentes velocidades (consumen los datos del sensor a diferente ritmo), cada uno puede llegar a leer un dato diferente en un instante del tiempo concreto; para que todos sigan siendo réplicas exactas y manden la misma orden al actuador, se usa un algoritmo de consenso para que todos los nodos/procesos usen el mismo dato y por ende, si el algoritmo es determinista, envíe la misma orden al actuador.
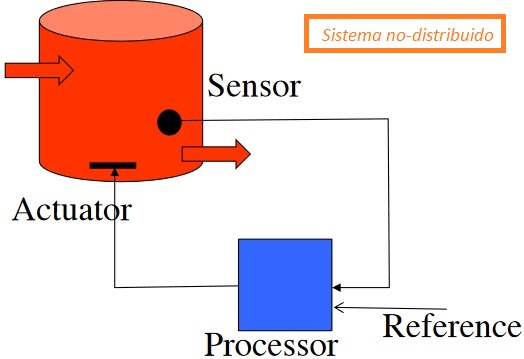
En un sistema no distribuido este sería el esquema sin tolerancia a fallos
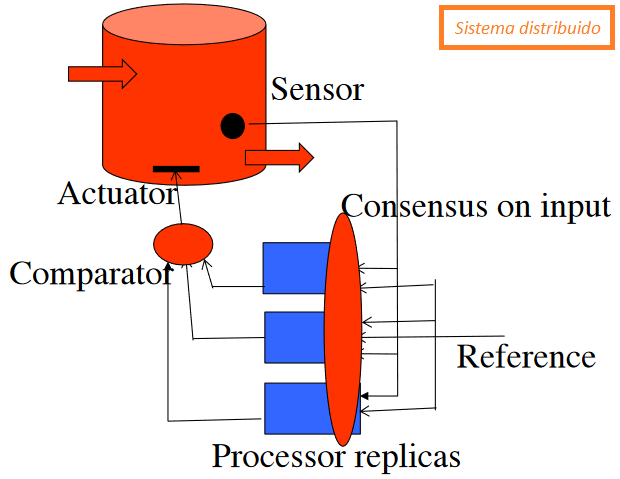
Un sistema distribuido de control con réplicas para la tolerancia a fallos
El sensor tiene un estado concreto y cada nodo lee dicho estado en un momento diferente del tiempo porque tienen diferentes relojes (esto puede significar que los relojes NO hayan empezado a leer los datos a la vez o que los relojes tengan diferente velocidad de lectura, provocando que un nodo consuma datos más despacio que otro, en momentos diferentes, etc).
Trabajo cooperativo
Sistemas distribuidos usados para la creación conjunta de un software o un documento (como ocurre, por ejemplo, en la concurrencia de varios usuarios sobre el mismo documento en Google Docs).
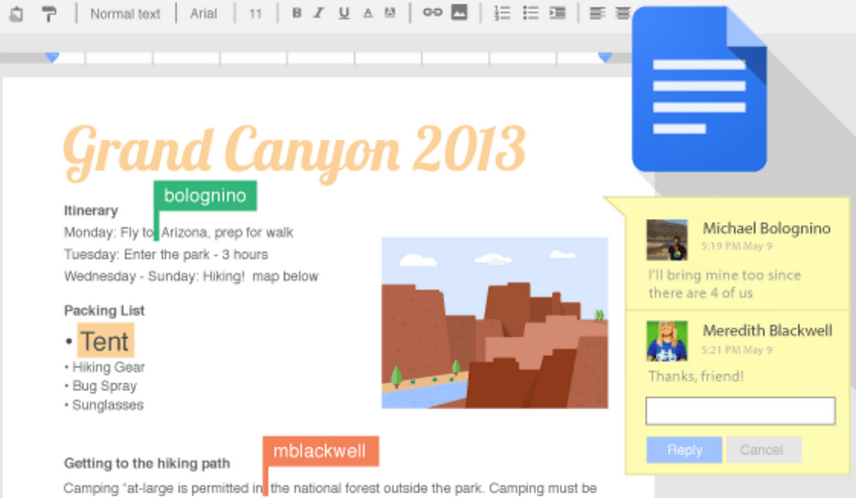
Normalmente usan un espacio con operaciones lecturas y escrituras y tienen que mantener una vista consistente del espacio (todos los usuarios/nodos tienen que ver lo mismo).
Para solucionar esto se pueden usar abstracciones de memoria compartida o sistemas de ficheros distribuidos; además, todos los nodos/procesos tienen que ponerse de acuerdo en el orden de las operaciones.
Bases de datos distribuidas
Sistemas distribuidos en los que se tienen que realizar transacciones distribuidas y por ende, sólo debe completarse la transacción si todos los nodos están de acuerdo, por ello se usa el algoritmo/abstracción de «atomic commitment«, concretamente, el algoritmo 2 Phase Commit.
Servicios de alta disponibilidad
Son sistemas distribuidos cuyo requisito de disponibilidad es fundamental para el correcto funcionamiento de la lógica de negocio.
Se consiguen implementar usando autómatas ó máquinas de estado (state-machine) replicadas, esto es, los procesos se ejecutan exactamente igual en todos los nodos: mismo código determinista, con los mismos datos de entrada y en el mismo orden. Es habitual usar algoritmos de consenso para conseguir que todos los nodos tengan el mismo estado (conocido como coherencia).
Normalmente también hacen uso de Bases de Datos distribuidas para conseguir replicar los datos de los que se nutren estos procesos replicados.
Computación distribuida
Modelo de computación que usa un sistema distribuido enfocado en el alto rendimiento computacional (high performance) para realizar cómputo paralelizado (distribución de la carga de procesamiento), lo cual requiere que el problema a resolver sea paralelizable, esto es, un problema dividible en subproblemas que puedan ser resueltos de forma independiente, es decir, que no requiera del resultado del sub-problema anterior para poder procesar el siguiente (por ejemplo, procesar cada una de las filas de una BDD). Es común usar estos sistemas para procesamiento de datos en el contexto del «Big Data».
Son ejemplos Spark y Hadoop y, en general, cualquier algoritmo capaz de ser paralelizado, como Map-Reduce.
Ejemplos de arquitecturas de SSDD
Cloud Computing
Cloud Computing es un ejemplo de aplicación de un sistema distribuido que ofrece servicios altamente disponibles mediante la capacidad de computación en servidores remotos bajo demanda (cuyos pagos también suelen ser por uso de computación, paga lo que uses). Dan la sensación de una capacidad de computación infinita de cara a la consumición.
Los CPDs en la nube tienen la ventaja de aprovechar al máximo su hardware mediante la multiplexación de los trabajos de los clientes (parecido a lo que ocurre en el algoritmo de Round-Robin en un SO) y de abaratar costes de compra debido a la «economía de escala» (compras al por mayor, cuanta mayor cantidad se adquiere más barato es el precio por unidad).
Un ejemplo de arquitectura cloud computing haría uso de los siguientes componentes:
- Ecosistema Hadoop:
- HDFS para ficheros distribuidos que contienen el código y datos necesarios para ejecutar aplicaciones en los nodos.
- Yarn para el acceso y gestión de HDFS, que es requerido para usar el código (gestor de aplicaciones) y datos en los nodos (los cuales son asignados por el gestor de recursos y de tareas).
- Servicio Zookeeper replicado para coordinar la replicación de todos los nodos (incluyendo el de su propio servicio) y su tolerancia a fallos.
- Un servicio de proxy replicado para redirigir al usuario al nodo o nodos concretos que se le han asignado (cada uno tendrá una IP+Puerto).
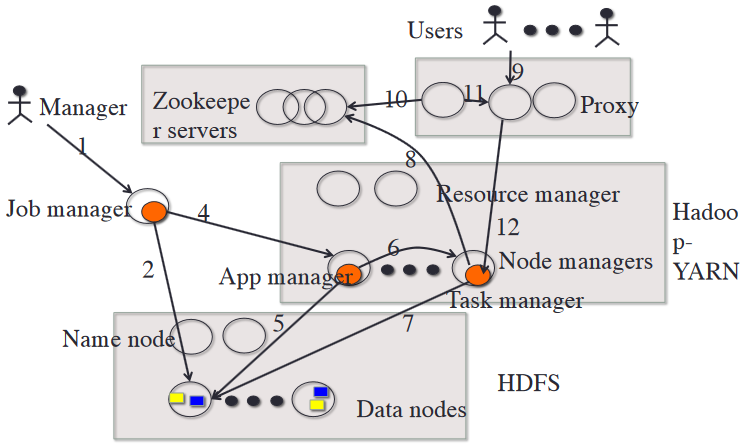
Con esta arquitectura un administrador puede añadir una nueva aplicación al servicio de cloud computing para los usuarios, la cual será replicada en HDFS (y el gestor de aplicaciones es notificado de esta nueva app para que se la pueda ofrecer a los usuarios).
Posteriormente un usuario accede al servicio a través de un proxy que le redirige a algún nodo que está corriendo la aplicación que desea usar. Todo ello de forma transparente al cliente.
Todos los sub-servicios de esta arquitectura están replicados mediante Zookeeper para que se mantenga disponible el servicio ante fallos.
Internet of Things (IoT)
IoT (Internet of Things) es un tipo de sistema distribuido cuya infraestructura pretende interconectar el mundo físico (Things) con el mundo virtual (procesamiento y reacción ante eventos del mundo real y virtual), mediante redes de comunicaciones (como Internet), creando así servicios avanzados para la sociedad de la información.
El IoT se puede ver, haciendo la analogía con el cloud computing, como un conjunto de pequeñas nubes que elevan información a nubes de más alto nivel hasta llegar a los dispositivos high-end (y posteriormente, si se desea, también a la nube). A estas pequeñas nubes también se les llama «nieblas» (fog), de ahí su nombre también «fog-computing«.
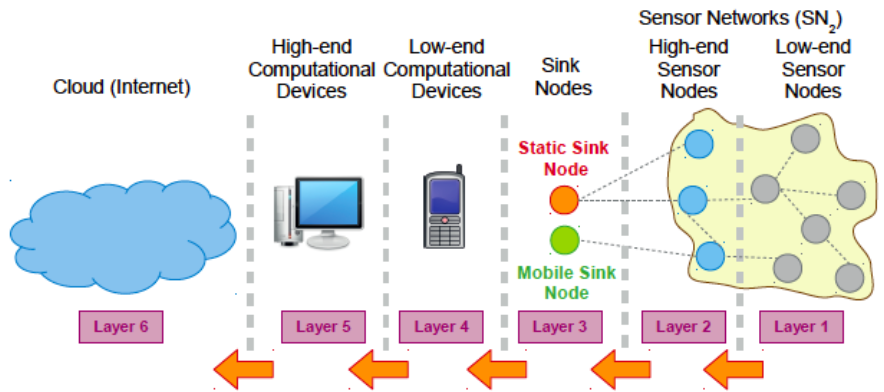
En esta arquitectura normalmente se usan sensores que emiten información (publicadores) y actuadores que consumen información (subscriptores), por tanto el paradigma de comunicación usado es indirecto (como Publisher-subscriber).
Los dispositivos edge (los que están más abajo en la jerarquía, como sensores y actuadores) se les llama things (la T del IoT).
Stream Processing
Cuando se tienen sistemas distribuidos, es habitual generar muchos datos (Big Data) en un corto periodo de tiempo, y es por ello que se usan técnicas de procesamiento y almacenamiento especiales: «Stream Processing» y «Event Sourcing».
- Stream Processing: hablamos de este tipo de procesamiento cuando se requiere digerir los datos casi en el mismo momento de su recepción. Esto implica almacenamientos ya procesados, con repeticiones, no normalizados… Hablamos de BBDD no-relacionales, para evitar el re-procesado de datos en caso de ser requerido por N usuarios.
- Event Sourcing: o fuente de eventos, es la técnica usada para almacenar la «fuente de verdad» que almacena el último estado de los datos. Hablamos entonces de BBDD relacionales.
Stream Processing y Event Sourcing se relacionan entre sí de tal forma que el primero se usa para análisis y pre-procesamiento de datos y el segundo para mantener el estado actual del sistema.
En cualquier caso, ambos sistemas van a necesitar de un conjunto de nodos o procesos que se distribuyan la carga de «fagocitar» los datos para que el sistema no se sature y sea capaz de almacenar, pre-procesar y analizar todos los datos en un tiempo razonablemente corto.
Kafka
Kafka es una herramienta del ecosistema de Apache que nos permite implementar esos procesos distribuidos que consumen datos según el tipo (tópicos/topics) al que pertenezcan, además de facilitar la tarea de replicación y tolerancia a fallos de los nodos a través de otra herramienta de Apache llamada Zookeeper.
¿Desea saber más? (TODO).
High Availability en SSDD
Replicación
Los sistemas distribuidos enfocados a la alta disponibilidad requieren de replicación para conseguir tolerancia a fallos. Concretamente replicación de:
- Procesos si requieren tolerancia a fallos (alta disponibilidad) en máquinas de estado (state-machine replica).
- Datos si requieren tolerancia a fallos (alta disponibilidad) en BBDD.
Importante recalcar que la replicación NO se va a usar para realizar cálculos/computación distribuida. Esta parte de un SD sólo existe para asegurar la tolerancia a fallos del sistema, es decir, la replicación sólo contempla el hecho de que los nodos puedan caerse o ser desconectados temporalmente de la red, no para aprovechar la capacidad de cómputo de todos los nodos como si fuera un super-ordenador (los cuales serían SSDD enfocados al «high performance»). En todo momento los nodos están ejecutando exactamente la misma tarea para mantener la máquina de estados (o datos) idéntica en todos los nodos.
Modelo
En la replicación se tienen sólo 3 componentes:
- Procesos distribuidos y concurrentes
- Datos replicados
- Operaciones de escritura ( W(<VAR>)<VALUE>) y lectura ( R(<VAR>)<EXPECTED> ). Siempre sobre variables, no sobre una instancia de una copia del dato.
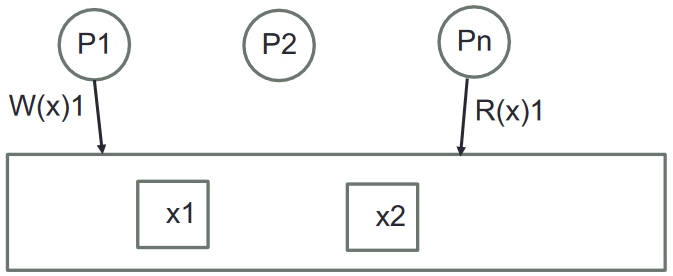
R(x)1 = Read from var X expecting 1 as result
Coherencia
Capacidad de mantener los mismos datos y estados en todos los nodos del sistema en el menor tiempo posible.
Tipos de coherencia
En orden de mayor a menor coherencia (respecto al tiempo):
- Procesos:
- Atómica (estricta o linearizable): es la coherencia que simula el comportamiento de una memoria interna de un solo nodo. Es la más costosa de aplicar y la que genera mayor latencia.
- Secuencial
- Causal
- Eventual: eventualmente todos los nodos estarán en un estado coherente. Se usa en sistemas no-críticos (ejemplo: tiendas online con stock no actualizado, el cliente recibe una cancelación de compra si finalmente no hay artículos disponibles).
- Datos / Transacciones:
- 1-copy-serializability: trata de conseguir coherencia sobre los datos replicados mediante algoritmos que creen transacciones distribuidas (replicación de datos) que sean equivalentes (a efectos de transparencia para el programador) a ser realizadas en un solo nodo.
Coherencia atómica
Todas las operaciones se ejecutan, en apariencia, de forma instantánea para el resto de nodos del sistema distribuido (y todos los nodos deben estar de acuerdo con dichas operaciones).
Formalmente hablando:
- Sea R(run) el conjunto de operaciones total del sistema.
- Sea alfa un subconjunto concreto de R.
- Sea «op» una operación.
- Sea el «orden de programa» ( <p ) la restricción que indica que una operación «op» va antes que otra «op’ » si la primera fue invocada antes que la segunda dentro de un nodo/proceso concreto (op <p op’).
- Sea el «orden de tiempo real» ( <rt ) la restricción que indica que una operación «op» va antes que otra «op’ » si «op» TERMINA ANTES de que «op’ » EMPIECE dentro de todo el conjunto de procesos/nodos del sistema (op <rt op’) . Si op’ empieza antes de que op termine, se dice que ambas ops se solapan y por ende su orden es intercambiable en la vista.
- Sea la «vista atómica» una secuencia de todas las «ops» de alfa que respeten <p y <rt.
- Sea una «vista atómica legal» aquella vista atómica que semánticamente tiene sentido, esto es, que cada lectura de variable tiene que tener al menos una escritura previa correspondiente y que el valor leído de una variable sea el mismo que el escrito inmediatamente antes:
- R(x) no es posible si no existe un W(x) previo
- W(x)V, R(x)V’ no debe darse
- Sea un «sistema atómicamente coherente» aquél en el que TODOS los conjuntos R tienen ALGUNA vista atómica legal (alguna ordenación de las operaciones del sistema es atómica y legal).
Coherencia secuencial
Aunque no se cumpla el orden de tiempo real, todos los procesos deben percibir el mismo orden de operaciones.
- Sea el «orden secuencial/de ejecución» (op < op’) si se cumple alguna:
- orden de programa (<p)
- op es escritura de X y op’ es la lectura de X (op=W(x)V & op’=R(x)V)
- cierre transitivo: si existe una op» tal que op < op» < op’.
- Sea la «vista secuencial» la secuencia de alfa que respete el orden causal.
- Sea una «vista secuencial legal» aquella que cumpla lo mismo que una vista atómica legal.
- Sea un «sistema secuencialmente coherente» aquél en el que TODOS los conjuntos R tienen ALGUNA vista secuencial legal.
Coherencia causal
Los procesos no tienen por qué ver TODAS las operaciones en el mismo orden que los demás, sólo deben ver en el mismo orden aquellas operaciones que causen un efecto sobre otras (orden causal de las vistas); o lo que es lo mismo, todos deben ver el mismo orden de las escrituras igual. Para ello:
- Sea «alfa-p» el subconjunto de operaciones alfa sobre un proceso p concreto que contiene las escrituras de todos los procesos y las lecturas de únicamente el proceso p.
- Sea la «vista causal de p» un orden de operaciones para el proceso p (alfa-p) que cumplen <p y <.
- Sea una «vista causal legal de p» si se cumple lo mismo que en la vista atómica para el proceso p.
- Sea un «sistema causalmente coherente» si, para TODOS los procesos del sistema, existe ALGUNA vista causal legal.
Coherencia eventual
Aunque este tipo de coherencia no está formalizada como tal, una definición intuitiva sería aquella en la que cada proceso tiene vistas diferentes y en la que, si se dejara de escribir, eventualmente todos los procesos acabarían leyendo la misma información, esto es, que eventualmente los valores de las réplicas acabarían convergiendo.
En este tipo de convergencia existen las llamadas «operaciones fantasma«, que son operaciones que se invalidan con el paso del tiempo porque no llegaron a «consensuar» en el sistema; obteniendo situaciones en las que un proceso escribe B pero se acaba leyendo A.
Tolerancia a particiones
En general, los algoritmos de tolerancia a particiones en los SSDD enfocados a la alta disponibilidad, deben seguir tres pasos comunes:
- Detectar que existe una partición.
- Pasar el sistema a «modo partición» para limitar las operaciones (normalmente de sólo lectura si es la partición con menor número de nodos, en otro caso continúa con funcionamiento normal).
- Tras recuperar la conexión, entrar en un proceso de «recuperación de consistencia», arreglando las discrepancias entre las particiones durante el lapso de tiempo.
Teorema de imposibilidad de CAP
El teorema de CAP nos dice que es imposible, en un sistema distribuido asíncrono o parcialmente asíncrono enfocado a la alta disponibilidad, mantener las tres características siguientes:
- C – Consistency: Refiriéndose a la coherencia atómica.
- A – Availability: Refiriéndose a la alta disponibilidad de los datos para su actualización (no para lecturas, ya que esa es relativamente fácil de conseguir).
- P – Partition-tolerance: Refiriéndose a la capacidad de poder continuar ejecutándose a pesar de producirse una partición de red.
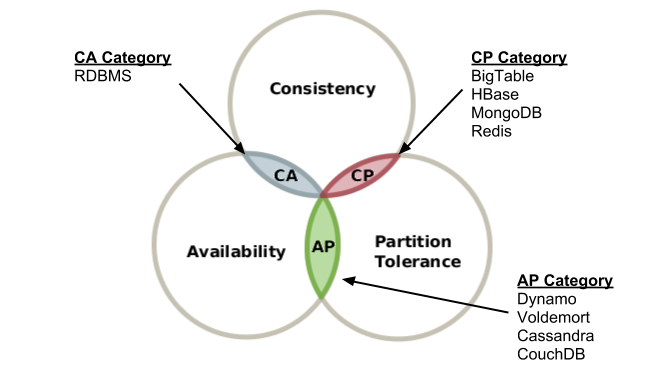
Cuando existe la posibilidad de que haya particiones de red, debe elegirse entre coherencia atómica (se puede usar otro tipo de coherencia menos restrictiva, como la eventual) y la alta disponibilidad.
En el contexto anterior tenemos modelos que eligen:
- AP – sistemas como los diseñados en torno a la filosofía BASE (Basically Available, Soft State, Eventual consistency), antagonista de diseños ACID y comunes en el movimiento NoSQL, eligen la alta disponibilidad sobre la consistencia, y usan una coherencia más relajada. Implementaciones: Cassandra y CouchDB.
- CP – usan BBDD que cumplan ACID. Por ejemplo el algoritmo de Paxos (implementado en Raft y Zookeeper).
- CA – SGBD relacional (en inglés RDBMS).
NOTA: Con frecuencia, el teorema de CAP se malinterpreta como si uno tuviera que elegir abandonar una de las tres garantías en todo momento cuando, de hecho, la elección es realmente sólo cuando ocurre una partición de red u otro de los posibles fallos; en cualquier otro momento, no hay que hacer concesiones.
Replicación de procesos: algoritmo Paxos
El protocolo Paxos fue publicado por primera vez en 1989 por Leslie Lamport aunque pasó desapercibido hasta 1998 cuando lo publicó en una revista especializada. Este es un algoritmo de consenso con cierto grado de tolerancia a fallos para la replicación de procesos (máquinas de estado) capaces de soportar errores crash-recovery .
Paxos elige CP del teorema de CAP: Coherencia atómica y Tolerancia a particiones.
Dos implementaciones de Paxos son Raft y Zookeeper (una herramienta del ecosistema de Apache); ambos funcionan igual a alto nivel.
Replicación de datos: transacciones distribuidas
Las transacciones distribuidas, además de ofrecer tolerancia a fallos, también dan alta disponibilidad de los datos.
Para satisfacer este modelo se usan principalmente los siguientes algoritmos:
- Two Phase Locking (2PL): Control de concurrencia local.
- Strict 2PL: Control de concurrencia global.
- Undo/Redo: Procolo de recuperación (crash-recovery).
- Two Phase Commitment (2PC): Protocolo de atomic commitment.
- ROWAA (Read-one-write-all-approach): Modelo para la coherencia serializable.
High Performance en SSDD
TODO / WIP
Acrónimos
SSDD: Sistemas Distribuidos.
SO: Sistema Operativo.
QoS: Quality of Service (Calidad de servicio).
CPD: Centro de Procesamiento de Datos.
Deja una respuesta
Lo siento, debes estar conectado para publicar un comentario.