Introducción
El protocolo Paxos fue publicado por primera vez en 1989 por Leslie Lamport aunque pasó desapercibido hasta 1998 cuando lo publicó en una revista especializada. Este es un algoritmo de consenso con cierto grado de tolerancia a fallos para la replicación de procesos (máquinas de estado) capaces de soportar errores crash-recovery en sistemas distribuidos.
Paxos elige CP del teorema de CAP: Coherencia atómica y Tolerancia a particiones.
Dos implementaciones de Paxos son Raft y Zookeeper (una herramienta del ecosistema de Apache); ambos funcionan igual a alto nivel.
Implementación de Paxos: Raft, Zookeeper
En resumen, tanto Raft como Zookeeper mantienen la replicación coherente mediante un log de operaciones realizadas (sólo escrituras) almacenado en memoria estable y que se deben mantener actualizados en todas las réplicas (ya que el log será el sistema a usar para que un nodo se recupere tras un crash). Hay una réplica líder que es la que atiende las peticiones de los clientes y que se encarga de la difusión del log entre las demás réplicas. Eventualmente el líder cambia, normalmente debido a crashes, retrasos en la red o por particiones de red.
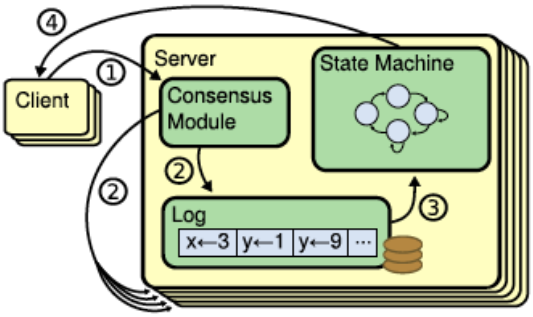
En esencia el algoritmo funciona así:
- Un cliente manda una petición a algún servidor del cluster, si no es el líder le devuelve la IP del líder.
- El cliente vuelve a intentarlo con el líder y este graba la petición en su log y
- realiza un algoritmo de consenso en dos fases:
- avisa a todos de la petición del cliente (para que lo apunten también en sus logs) y, si obtiene una mayoría de ACKs (el sistema es conocedor del número de réplicas, membresía conocida) procede a ejecutar la operación en su «máquina de estados» (su proceso replicado en memoria volátil) y
- avisa a las demás réplicas de que ejecuten también esa operación en sus procesos (para mantenerse en un estado actualizado).
- Finalmente el líder le devuelve una respuesta al cliente de la operación.
La verdad de la mayoría: La coherencia en Paxos, procederá (casi) siempre de que haya una mayoría que apoye algún paso o información almacenada que entre en conflicto con algunos nodos; ya que es lo único en lo que podemos basarnos como «la verdad» de lo que ha ocurrido dentro de un sistema donde puede haber particiones de red.
Viveza del consenso (consensus liveness): Por tanto, si la mayoría de los nodos están caídos (ya sea de forma real por crashes o debido a particiones de red), el algoritmo se vuelve «indulgente«, esto es, evita los fallos esperando a que haya una mayoría de nodos activos. Es por esto que se debe elegir un número impar de nodos (la mayoría se tiene en cuenta sobre el total de nodos del sistema, no de la partición).
Componentes
- Procesos:
- Dinámicos
- Tolerantes a fallos crash-recovery (suponen seguridad, no ataques)
- Asíncronos
- Enlaces (links):
- Asíncronos
- Fiables (FTP)
- Pueden caerse (particiones de red)
- Paradigma de comunicación directa por RPC
- Máquinas de estado:
- En memoria volátil
- Código determinista
- Aseguran operaciones ejecutadas «at-most-once» (almacenando la última petición del cliente en memoria volátil).
- Coherencia atómica
Axiomas
- Legislaturas = Tiempo. El tiempo, en el algoritmo de Paxos, se divide en legislaturas (terms) numeradas incrementalmente; estas serán los time-stamps del sistema (a modo de relojes lógicos) usados para saber qué nodos están desfasados; cualquier nodo que reciba alguna RPC (incluyendo respuestas de peticiones) de una legislatura superior a él, se convierte automáticamente en seguidor de esa legislatura.
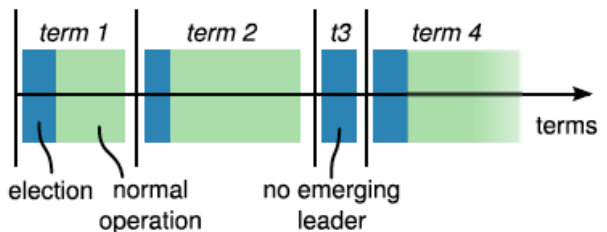
- La tolerancia a fallos crash-recovery de los procesos se consigue almacenando en el log las operaciones de escritura realizadas.
- El log está dividido en índices (indexes).
- Cada entrada del log contiene: índice, comando y nro. legislatura.
- Una entrada del log se considera consolidada/comprometida (commited) cuando está registrada en la mayoría de nodos.
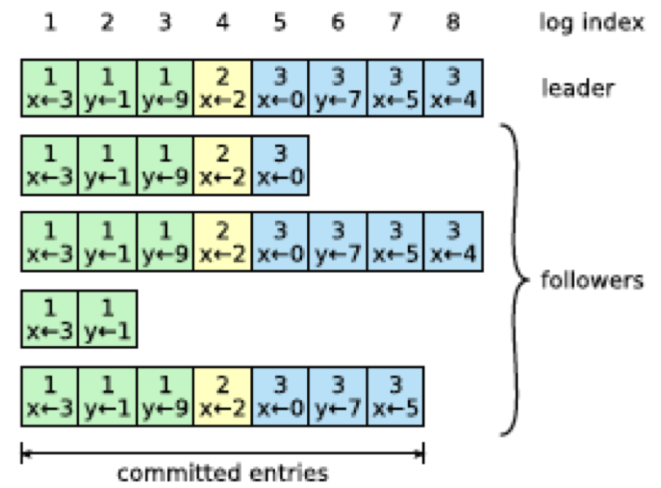
- Los nodos sólo pueden estar en 3 estados: líder, seguidor (nodos pasivos que esperan órdenes del líder) o candidato (a líder).
- Los nodos siempre empiezan como seguidor.
- El algoritmo de Paxos sólo puede continuar si existe un líder.
- El líder elegido debe ser «distinguido» (tiene que tener todas las entradas comprometidas del sistemas en su log).
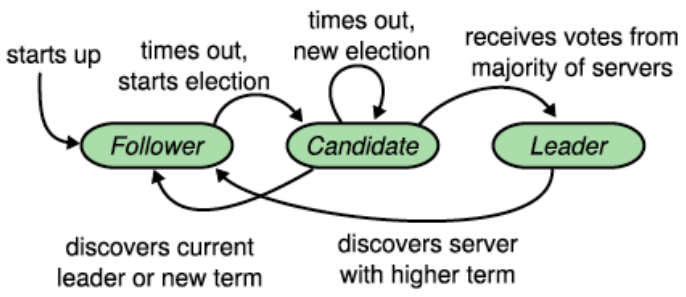
- El líder manda periódicamente HeartBeats (HB) a los seguidores para indicar que sigue online.
- Los seguidores tienen un TimeOut (TO) aleatorio (entre 20 y 500 ms).
- Todas las órdenes enviadas incluyen la legislatura actual del nodo que la envía.
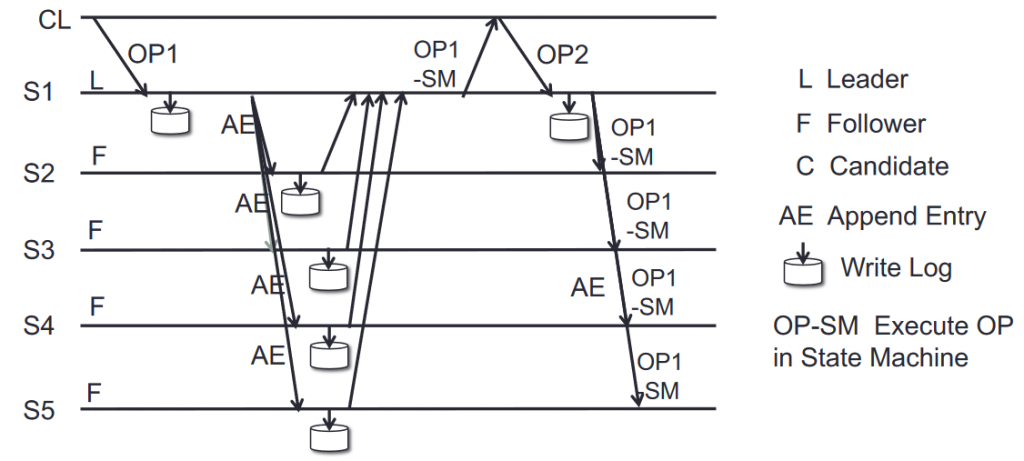
Replicación del log
El líder es responsable de la disfusión del log mediante consenso de dos fases:
- Aceptar petición de cliente
- Apuntar operación en el siguiente índice del log
- Enviar orden AE (Append Entry on log) a los nodos de forma indefinida hasta que contesten (incluso después de que el líder haya completado su operación).
- Si obtiene la mayoría de los ACK’s antes de un TO, realiza la operación en su máquina de estados, y esta queda comprometida.
- Avisa a los demás nodos de que pueden aplicar la operación en sus máquinas de estados.
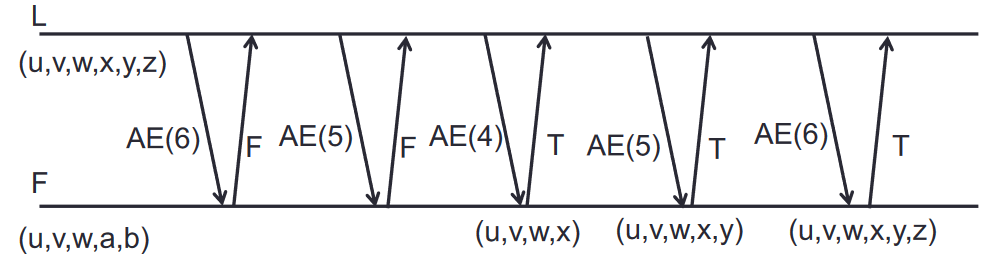
Coherencia del log
Las órdenes AppendEntry (AE) del líder incluyen el índice actual + el anterior índice del log + la legislatura del índice anterior. Para mantener el log coherente, cuando un seguidor recibe una orden AE de su misma legislatura:
- Verifica que exista el par [índice + legislatura] previo (que le manda el líder con AE) en su log.
- Si no existe, rechaza la orden, indicándole el fallo al líder.
- El líder vuelve a intentar la orden AE del índice anterior hasta que encuentre un índice en el que ambos coincidan. Desde ahí, el líder empieza a mandarle las órdenes AE en orden que tiene almacenadas hasta llegar al índice actual (y obviamente, machacando las entradas del log que tuviera el seguidor).
NOTA: Para evitar que un líder con un log «desfasado» machaque la info de los demás nodos, se restrinje la elección de lider a uno «distinguido».
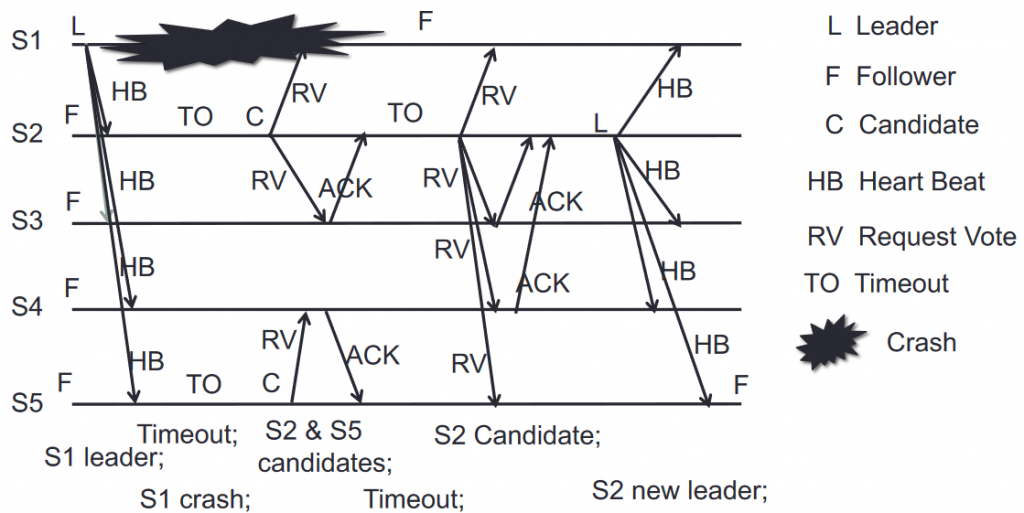
Elección de líder
Cuando el líder cae por crash, TO ó quedar al otro lado de una partición de red:
- Eventualmente algún seguidor alcanza su TO y se proclama candidato, momento en el que se incrementa el número de legislatura.
- El candidato comienza a pedir votos y establece un TO de elección aleatorio (entre 20-500ms) para evitar un deadlock entre dos candidatos simultáneos.
- Los nodos votan sólo al candidato que se lo haya pedido primero (1 x FIFO) y que esté al día (su log contiene el mismo índice y legislatura -o superior- que el log de los demás).
- Si se alcanza el TO de elección o no se obtiene la mayoría de votos (incluido su propio voto), vuelve a «convocar elecciones» (incrementando el número de legislatura, usando otro TO) hasta que lo consiga o descubra que ya existe otro líder (a través de la respuesta de petición de voto o mediante algún RPC de otro líder que no esté desfasado).
NOTA: Un candidato sólo puede resultar ganador si su log contiene todas las entradas comprometidas del sistema, o, de forma simplificada, si está al día (índice y legislatura al día).
NOTA: El tiempo de TO de elección debe estar comprendido entre el tiempo de broadcast y el MTBF (Mean Time Between Failures) del servidor.
broadcastTime<< electionTimeout << MTBF
Safety properties
Raft asegura las siguientes propiedades:
- State-machine safety: todos los nodos aplican la misma operación para un índice de log dado (porque la operación sólo puede aplicarse cuando hay consenso y por ende mayoría y por ende coherencia).
- Election Safety Property: sólo puede existir un líder como máximo en cada legislatura, pues requieren de una mayoría de votos.
- Log Matching Property: si dos logs contienen una entrada con mismo índice y legislatura => ambos logs tienen las mismas entradas desde ahí hacia atrás.
- Leader Completeness Property: si una entrada del log está comprometida para una legislatura concreta => esa entrada estará presente en todos los líderes de legislaturas posteriores.
Deja una respuesta
Lo siento, debes estar conectado para publicar un comentario.